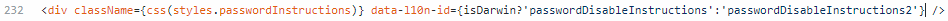In this lab, we fix an issue in Brave and then build tests for our fix.
The Issue
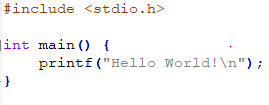
Brave parses text entered into the URL bar to determine whether it’s a URL or search term. However, there is a bug that if a space exists anywhere in the string that’s not at the beginning or end, it assumes it’s a search string. This means entering “https://www.google.ca/search?q=dog cat” will cause Brave to think we’re literally searching for “cat” and “https://www.google.ca/search?q=dog”.
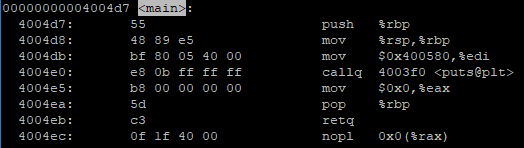
Current build of Brave
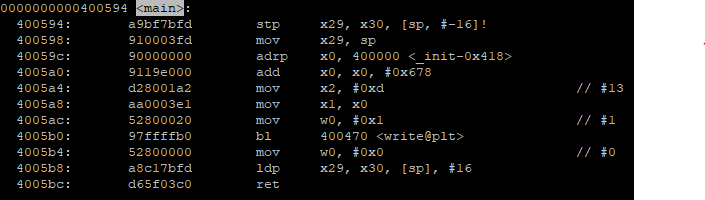
For comparison, other browsers like Chrome sees that as a URL by replacing the space with “%20”.
Chrome
The Fix
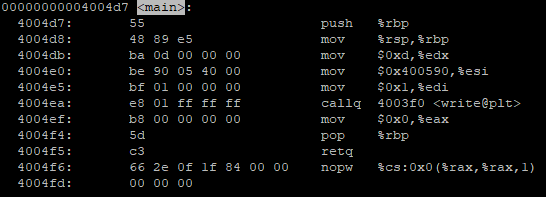
Fixing this was really simple: Add a line into urlutil.js that replaces all spaces with “%20”.
And now, URLs with spaces in them will be parsed as URLs instead of search strings.
My build of Brave with str.replace
Testing
After running a test, we find that there are some tests in place that checks that text with spaces in the URL bar should not be considered a URL. By editing these tests to return the opposite – because they are being treated as URL by the browser – the tests pass.
For this lab, we installed Visual Studio Code as well as built our own version of it.
VSCode has proven to be a very useful… lightweight?… tool in coding throughout this course. Being able to code, build, debug, and test code in VSCode has made developing code much easier!
I didn’t install any extensions. I found that what was available by default gives me everything I needed for this course up to now. Perhaps I should explore what extensions are available.
Building my own version of VSCode
I did have some difficulties at first with trying to build VSCode on my machine. Mainly it had to do with the prerequisites. After scratching my head for a second, I decided to just uninstall the prerequisites and try again from the top. I’m not sure which step I missed or did wrong, but the build completed successfully the second time through!
Live Debugging
Arguably the best part of VSCode. It took me a while to get the hang of it at first because this was all new to me. Even in INT422, which we used Visual Studio, I never used the live debugging feature.
Now, I used the live debugging feature when working on releases 0.2 and 0.3, as well as lab 6. Being able to see what was going on with the code while being able to make changes to it live was like magic. No joke. I can’t go back to the old ways of Notepad++ and Vim, saving, building, testing, and then manually figuring out what happened.
Electron
This is also when I was formally introduced to Electron. I have used another program built with Electron – Discord – but I never knew what it was back then.
So what is Electron?
It’s an open source framework for creating desktop apps like it’s a web app. Essentially using HTML, JavaScript, and CSS to make desktop programs.
For this release, we were tasked again to contribute to an open source project, with the idea of doing something “more” than in our previous release. “More” in this case means doing something different or more challenging so we can grow as contributors.
Returning to Brave
I decided to focus on Brave again for this release because I was already familiar with the project from before. Fixing the issue I chose for Release 0.2 has taught me a fair amount about Brave’s inner workings.
Growth Goals
In order for us to grow, we had to aim higher. We were given some suggestions of goals to help us, and these were the ones that I chose:
get more involved in the community
to work on more bugs than last time
to gain more experience in different areas of contribution
Originally, I picked to work on more bugs than last time. However, due to the time it took to discuss the first bug I took on, I figured that working on multiple code-related issues would not be feasible. In order to achieve my first goal, I also had to look into another area of contribution and that was to update their documentation.
Achieving My Goals
Joining The Community
For Release 0.2, all I did was comment on a triaged bug that I wanted to work on it and then created a pull request. I never got involved with the community at all.
This time I joined their Discord and took part in discussions. I also chose to work on a more recent issue that was getting some attention. I brought up the possibility of localization issues that the fix would introduce, as well as my approach to resolving the issue.
Working On More Bugs
Working on more bugs seemed like it would be simple at first. However, as I mentioned in the previous section, it did come to a point where it didn’t seem like it would be possible. Getting feedback was pretty quick at first, but as the week drew to a close, responses were taking longer and eventually I got no responses at all. Brave is currently undergoing a big upgrade so it’s likely all team members were focused on that.
In order to achieve this goal, I had to find issues myself. I assumed that finding code-related issues would be very difficult, so I found issues in their documentation instead. This would be more beneficial to me as I hadn’t contributed to documentation in the past, and I can make that a growth goal!
With those two issues, I’ve basically achieved this goal. I know it’s only one more than my previous release. I did originally aim for 3, but I had to downscale due to time.
Gaining Experience In Other Areas Of Contribution
To achieve this goal, I went through Brave’s documentation. I originally expected that I’d only be fixing the odd typo or grammar error. Luckily, it didn’t take long to find a document that was outdated and had a glaring mistake.
My Contributions
Improving About:Passwords
This issue was filed by a collaborator. In Brave, about:passwords is a page that lets users manage the passwords the user allowed the browser to store. At the top of the page, it instructs the user where to go if they want to change how their passwords are stored.
Context menu on Mac
Currently, the page suggests users go to Preferences > Security. In some ways, there’s nothing wrong with this because, on MacOS, Windows, and Unix, the name of the menu to access the Security section is called “Preferences”. Additionally, the URL to get to Preferences is “about:preferences”.
The issue occurs when users try to access Preferences through the context menu. On MacOS, the option in the context menu to get there is aptly called “Preferences”. However, on Windows or Unix, the same option is called “Settings”. Now the instruction may not make sense to some users on using either of those two operating systems. Savvy users may figure out that it means “Settings” because it leads to about:preferences. Other users might go looking for a “Preferences” option.
Context menu on Windows
There are two ways to fix this: Either remove the check in the context menu that checks for the OS and changes “Preferences” to “Settings”, or add a check to about:passwords that changes the instructions. I assumed that there was a reason for the different name and that the check was added in later in development. With that, I approached the issue with the second option.
Working On The Solution
There are three files responsible for the passwords page:
about-passwords.html – the page that is loaded but we can ignore this file
passwords.js – renders the content. It’s referenced by the HTML file, and uses strings from…
passwords-properties – the localization file
Currently, in passwords-properties, the string for the instructions is stored in one variable.
This needed to be split into three: One that holds the instruction that is common for all three OS, one that holds part of the instruction specific to MacOS, and one that holds the part of the instruction specific to Windows and Unix.
In passwords.js, I needed to modify this block of code that changes which instruction is displayed depending on the OS.
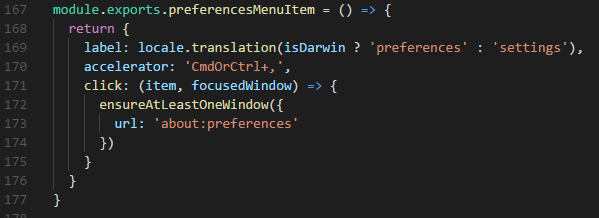
First I needed to import “isDarwin”, which is a function built to check if the OS is a Mac.
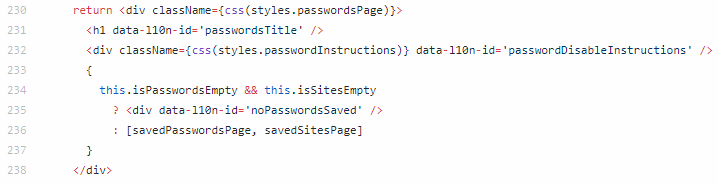
I changed the above block of code so that the text is in two <span> tags inside the <div> at line 232. The first span would have the ID matching the common instruction, and the second span would use an inline condition statement to change its ID depending on the OS.
The user who reported the issue also suggested making the instruction a link that takes the user to the Security page, hence why the second span has an onClick property.
I added a bit of styling to make the link apparent. For the most part, it seems to work, but when I asked a friend to test my branch on their Mac, the link wasn’t orange.
How it appears on WindowsHow it appears on Mac
For the sake of the assignment, and with the approval of the collaborator, I created a pull request labeled “work-in-progress”. Though the semester is over, I really do want to see this issue through to the end.
Updating componentStructure.md
The componentStructure.md document is extremely outdated. This document explains how a component is created – what it extends – the hierarchy of the compoenents, and a glossary explaining each component’s function.
Most of the information in that document reflects what Brave was like 3 years ago! It has changed drastically in that time.
On the image to the left, you can see that there are only a small handful of components. A cross-section of what Brave was like in it’s early life. Back when every component was stored in the js directory.
Today, Brave has well over 100 components. Some components have been restructured and renamed as well.
3 months ago, a contributor updated the hierarchy to what you see on the left. However, the contributor erroneously thought that it meant the directory structure of Brave’s components. It’s actually a structure of how each component references another. So now, the hierarchy is a strange mix of an outdate component tree and its current directory tree.
For starters, the very first line in the document states that all components extend ImmutibleComponent, which in turn extends React.Component.
This is no longer true. A quick look at many components shows that they extend React.Component directly:
So I changed this like so:
The hierachy needed a serious update. Some components like “App” has been changed to “Window”. I undid the changes made by the previous contributor which replaced “Main” (a component still in the program) with “Renderer” (a directory). Then I added every new component Brave uses. This added over 100 entries, totaling 180 items in the component hierarchy.
To give you an idea of how much has changed, see above how Main (or Renderer) directly uses 4 components. This is how many components Main uses now:
I added the new components to the glossary and explained them to the best of my ability.
Because I won’t be available for most of Sunday to write this blog, I’ll write it now.
Summary of Progression
I had difficulty finding a project to work on. I tried a variety of different projects on Github, but many of them had problems being installed on our servers, such as requiring immintrin.h. With stage 1’s deadline approaching, I hastily picked a project what I would end up abandoning because the only way to benchmark it was infeasible. I later settled on HashRat after learning how to generate a large file of random data.
My approach to optimizing HashRat is akin to throwing things at a wall and seeing what sticks. I went through everything from changing the optimization level to trying inline assembler. My biggest breakthroughs, I think, are when I discovered the second Makefile that was responsible for compiling the algorithms, and how to enable the optimized version of the transform function.
Increasing the optimization level in the other Makefile had a small but noticeable improvement. It was enabling the optimized function that made the biggest improvement. This is because the function unrolled most of the loops. Unfortunately, my attempt at inline assembler turned out fruitless.
In the end, I created a pull request that only enabled the optimized function by default. I didn’t want to use the O3 flag because I hadn’t tested it on the other algorithms used by HashRat. I submitted an issue and pull request, but so far haven’t seen a reply.
Analysis of Results
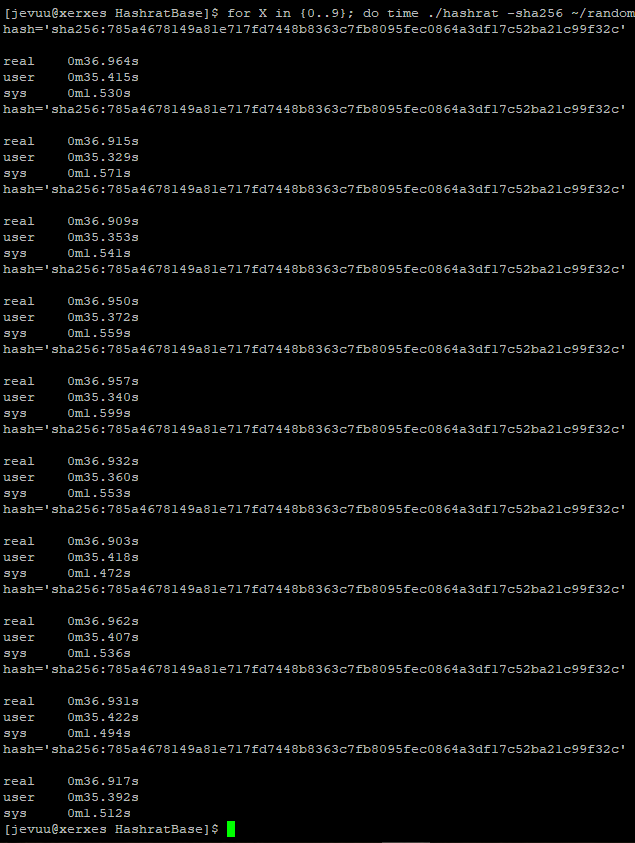
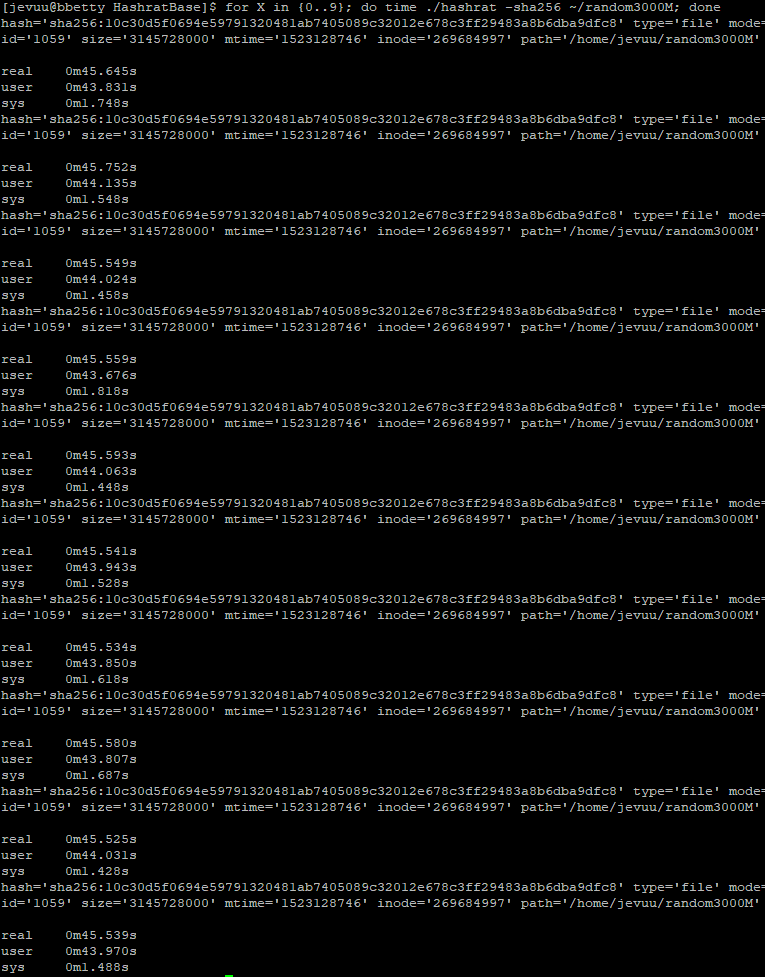
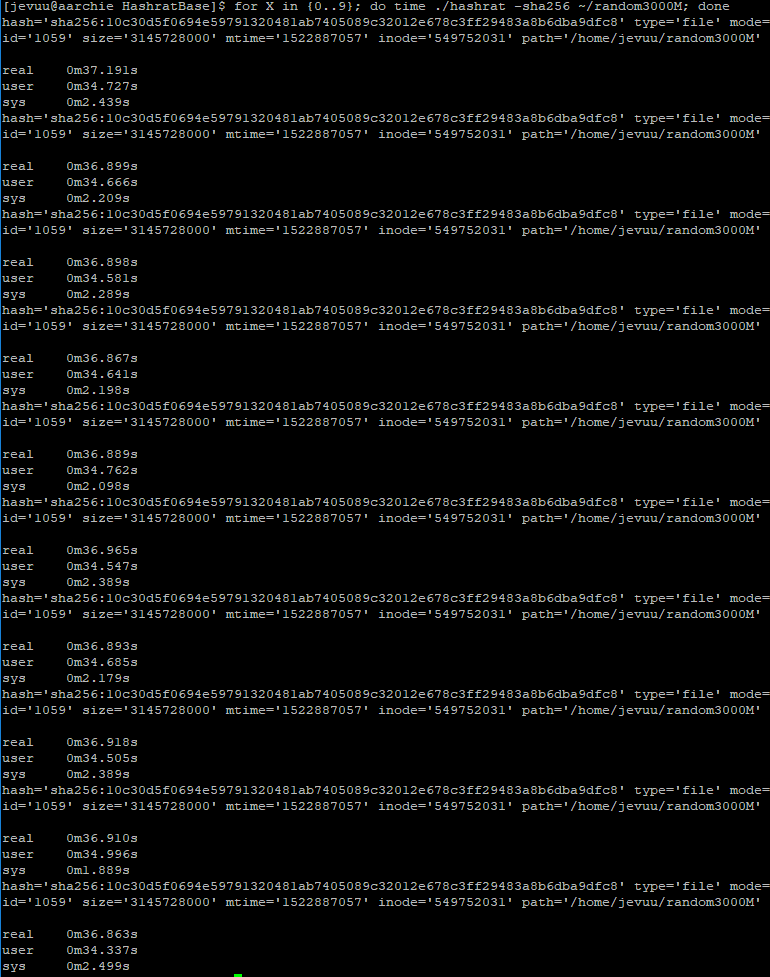
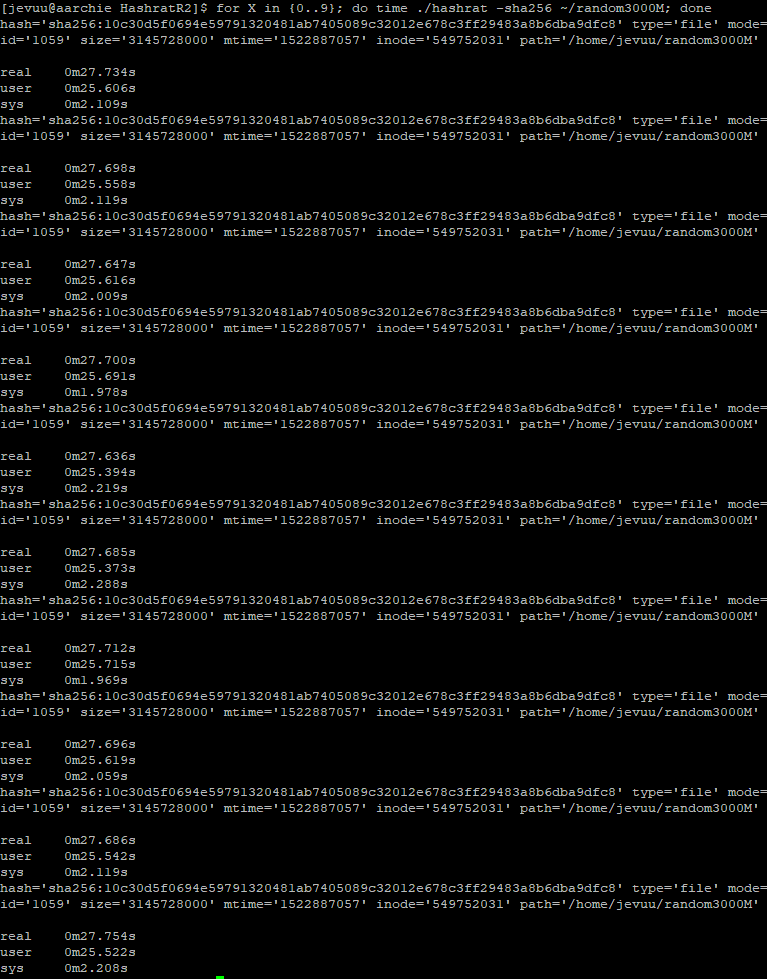
Running the original build on Xerxes, BBetty, and AArchie produced different run times. This was expected, especially for BBetty, because of their different specifications and architecture. Xerxes and AArchie hashed a 3GB file in about 36.9 seconds, while BBetty was the slowest taking 45.5 seconds.
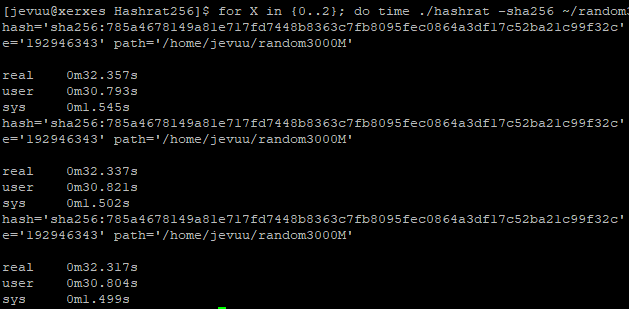
With just the O3 flag in the proper Makefile, I saw a very small improvement. On AArchie, there was about a half second improvement. Xerxes saw a greater improvement of about 1 second. I didn’t test this approach on BBetty.
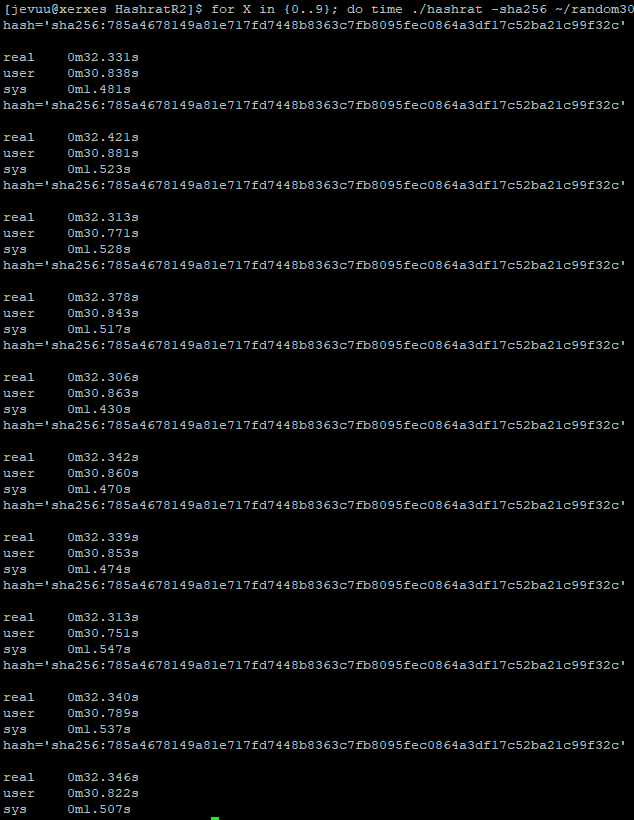
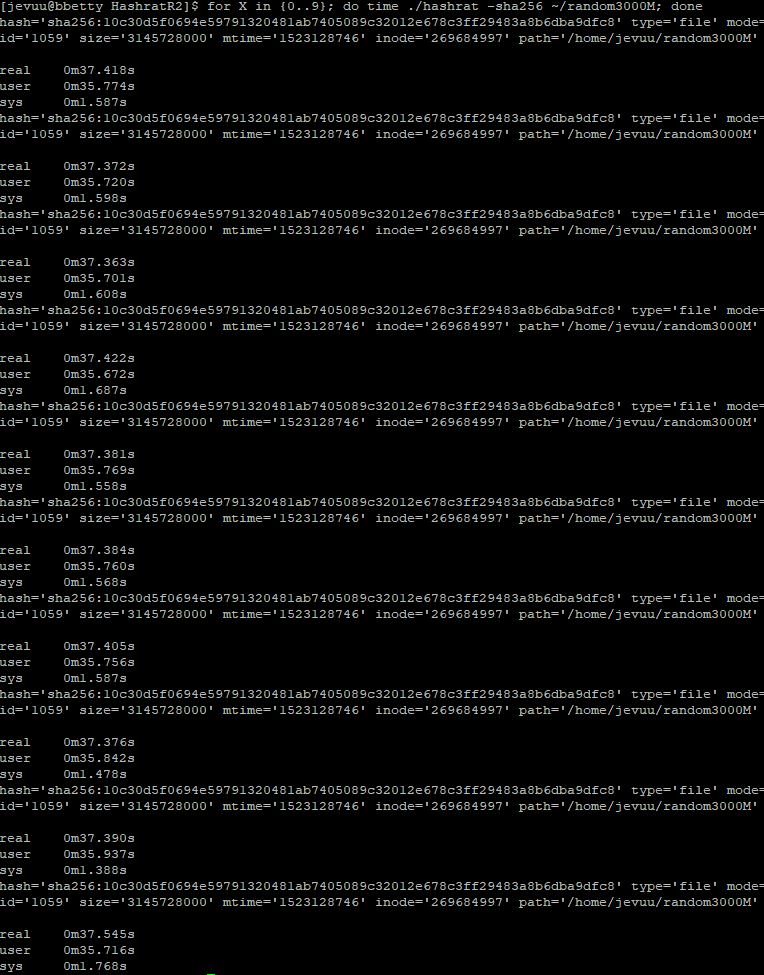
With the unrolled function being used in addition to O3, all 3 servers saw a significant increase in performance. Interestingly, the improvements were much better on the AArch servers compared to Xerxes. Xerxes was only 11% faster in total. AArchie, on the other hand, shaved a quarter of its time.
In the slower version, the loops are iterated 16 and 64 times respectively. This will likely produce many jump instructions. Values of the variables are also being changed at the end of each iteration.
In the unrolled version, the loops are only iterated 2 and 8 times respectively. Directives set up to take in values like a function are used 8 times per iteration. Because the compiler replaces every reference to the directive with its value, it’s essentially like 8 inlined functions. This also means the program won’t need to swap the values of variables, it simply changes the order they’re passed in.
This 2 times
as opposed to this 16 times.
And that’s not even counting the otherworldly math going on.
Reflection
I think this is possibly the hardest project I’ve ever been given in my academic career.
I think I could have improved my process if I had a better understanding of how to optimize. I’ve honestly felt very lost throughout the course, and this project was very daunting. I think I only have myself to blame because the professor gave every opportunity to clarify topics covered in class and help with projects.
It was great that I managed to find something that helped improve performance, and it was right there in the code.
However, I wish I was able to figure out assembler. The reason I dared to try inline assembler was that I wanted to push myself. I was inspired by someone else’s attempt at rewriting the same function in assembler. Unfortunately, I couldn’t figure it out and didn’t make any progress on that side.
I also should have attempted to contact the project’s author from the beginning. I forked the project and worked on it without ever trying to communicate with them. I feel that this might have made my issue and pull request come off as rude.
I also should have looked for a more active project. Having an actual community or active authors would have helped me greatly in understanding their project, where it needs improvement, and how to improve it.
One takeaway from this course is that I should always review my code thoroughly to check for any unnecessary calculations, unused variables, and minimize the use of loops with many iterations.
I noticed I haven’t submitted this lab even though I’ve done a good portion of it. Huh.
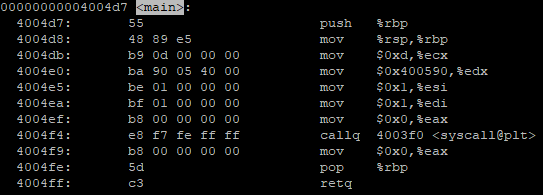
In this lab, we experimented with assembly and how it can affect the program.
We were given a set of code in C which all produce the same output, but written differently. The code and their filenames are as follows:
hello.c
hello2.c
hello3.c
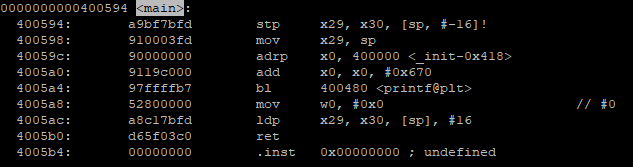
After compiling them in both AArch64 and x86_64, we took a look at their object code and compared them:
hello
hello2
hello3
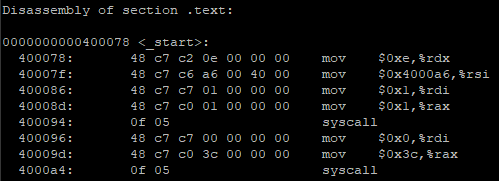
Afterward, we compiled the assembler versions for the two architectures. We noticed that all the extra sections that were in the C object code aren’t in the assembler object code.
AArch64:
x86_64:
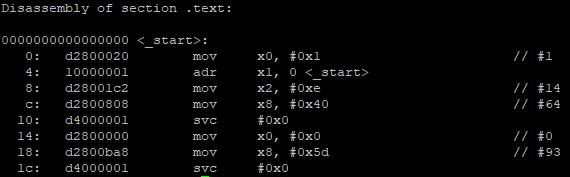
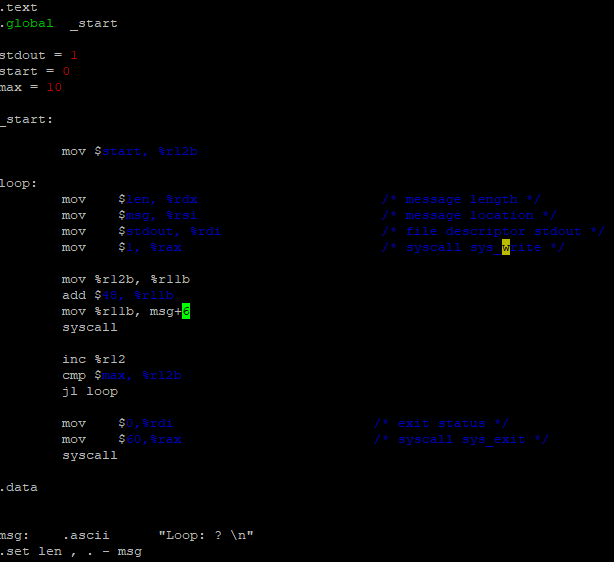
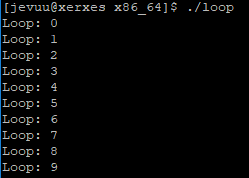
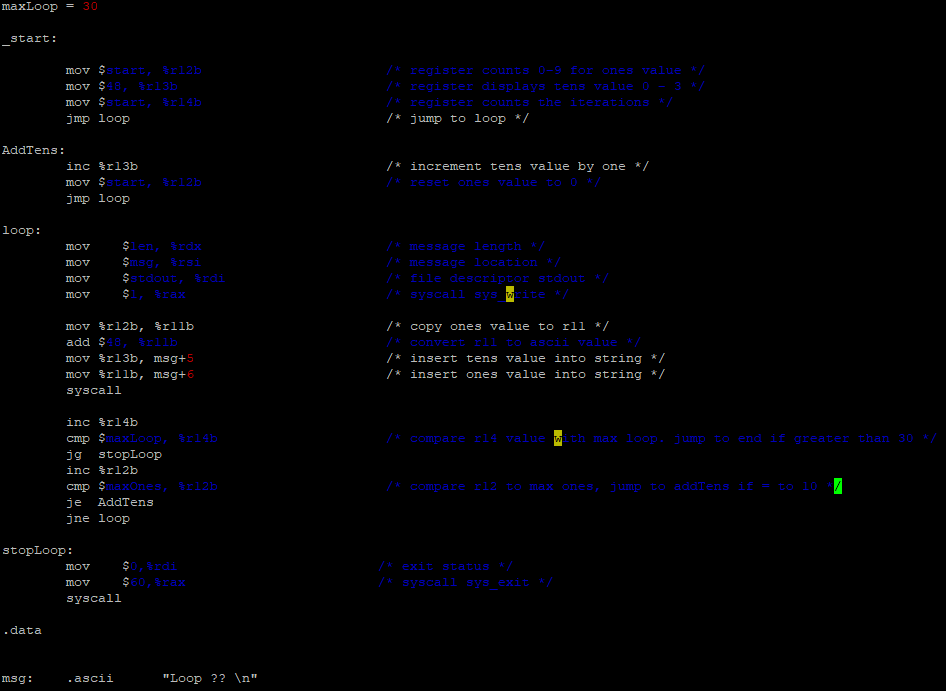
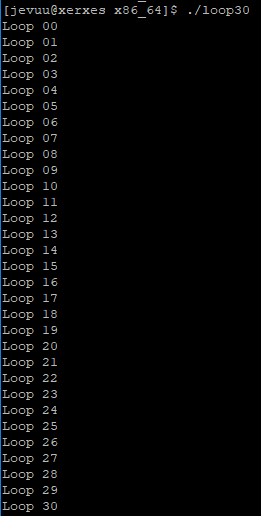
Then we tried building a program in assembler that loops and prints the iteration number. First we did it in x86_64, and this is how it looks like and what it outputs:
We then modified the code so that it loops 30 times and prints the iteration number properly. This was also done in x86_64:
Summary
Assembler is hard. This lab has made me appreciate high-level code more than ever! Figuring out how to code the looping programs in assembler was very satisfying, maybe because I can finally stretch after being hunched over staring at jargon for minutes on end.
Even after completing this lab I’m still confused about it.
Github pull requests not being looked at? If not, then…
Did you update your Github profile with your name and bio? Does your profile picture have a picture of you?
If you answered “No” to any of these, that’s probably why. One thing I learned from the Technician As Entrepreneur course (TEC702) is that you build trust by providing a picture of yourself and providing a bio – who you are and why you’re doing what you’re doing. This is reinforced by this comment here.
So, add a picture! Put your name on your profile! Provide a bit of info on yourself! And you’ll improve your chances of getting a response.
By not providing a picture, name, and/or bio, you’re a completely anonymous person trying to offer assistance. Sounds familiar? Like a complete stranger approaching you or at your front door trying to sell you something. Looks shady.
Even in social sites like Facebook or Twitter or Reddit, if you see an account that’s sending you messages or trying to friend or follow you, but their account provides no information on them, you probably wouldn’t reply or accept their request.
To the authors of the project, this is what they think when they see your freshly made Github account with a blank profile and a few small projects that you did for class.
I hope the author is nice. In retrospect I really should have tried reaching out to them at the beginning of the project. By filing the issue and pull request now, I feel like I’m coming off a little rude.
Whew with a little over a week to go, I’m going to dive into Release 0.3. I think for this release I’m going to tackle multiple issues, and maybe scale up in difficulty as I go through them.
About:Passwords – Brave Browser
My first issue will be, again, Brave browser. Here’s the issue in question: https://github.com/brave/browser-laptop/issues/13793.
The instructions aren’t exactly wrong, because on MacOS, the menu option reads “Preferences”. This issue is specific to Windows and Linux which display “Settings” instead.
This bit of code from a different part of the browser certainly suggests that to be the case:
So let’s go straight to the relevant parts of this issue. After a bit of digging around, I discovered two files are responsible for the about:passwords page: passwords.js, and passwords.properties. The first file is responsible for the design of the page, and the second contains the localization strings for the US English locale.
In passwords.js, this is the block of code I’ll need to modify:
We can see on line 232 that the contents of the div is defined by the l10n (localization) ID, with the ID being the name of the variable in the relevant locale file.
One way to deal with this issue is to add an inline conditional statement for data-l10n-id at line 232. So, if the OS is Mac (a.k.a. Darwin) then it displays the string with the original instructions, but if its another OS, display a different string.
This somewhat fixes the first part of the issue. This fix opens a new can of worms for localization, however, because there is now a new string to localize in all the languages Brave currently supports. I brought this up in a comment on the issue:
I’ll have to wait and see their reply.
In the meantime…
I continued to see how I can insert a link. Currently, the text is a <div>, which to my knowledge can’t be a link. And personally, I’d prefer if only “Settings(Preferences) > Security” was a link, and not the whole line.
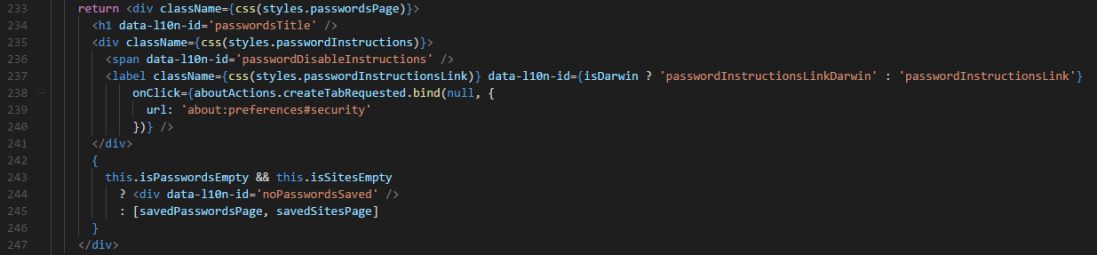
After a bit of fiddling, I came to a solution. I split the string so that the static part – “To change how passwords are managed, go to ” – is its own string with the original name, and “Settings(Preferences) > Security” are two strings called “passwordInstructionsLink(Darwin)”.
I moved the localization ID out of the <div> and into a <span> tag nested inside. Then, the “passwordInstructionsLink” strings were placed in a <label> tag, with an additional onClick event property.
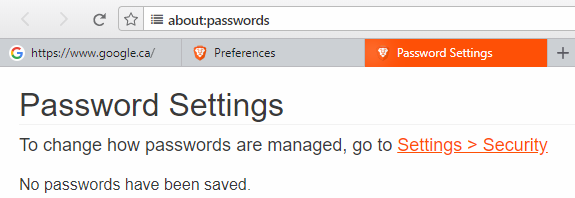
And here’s the result!
New Challenges
However nice this looks, this does make localization much more difficult because it separates one sentence into 3 strings. On top of that, some locales have additional words after the directions which are probably be static.
If I want that to be regular text, that would probably mean splitting the sentence into 4 strings for localization. I hope that won’t be the case.
Link to branch: https://github.com/jevuu/browser-laptop/tree/passwords
It’s been a busy week of research, trial and error, progress and dead ends. To recall, I decided at the beginning of the week to work on Hashrat, a tool that hashes files with a variety of algorithms. Originally, I was going to work on the MD5Transform function but ended up mostly working on the SHA256 hash functions.
I took a couple different approaches to try and optimize the program. I first tried changing the build options through the Makefiles, and then later looked at the code itself to try and make compiler optimizations. A couple days ago, I challenged myself to try inline assembly, but that is currently a work in progress.
My changes to the program produced a varying increase in efficiency. When benchmarking the original and optimized version of Hashrat on Xerxes, there was about 11% increase in efficiency. On BBetty, the optimized version was about 17% more efficient than the original. The optimized version on AArchie was remarkably 25% more efficient.
The program on all servers hashed 3GB files but Xerxes had a different file hence the different hash it generated. However, you can see that the resulting hash output by the original and optimized versions were not affected by my changes.
Xerxes
Original version of Hashrat hashes a 3GB file at 36.9sOptimized version hashes the same file in 32.3s
BBetty
Original version of Hashrat on BBetty took 45.5s to hash a 3GB fileThe optimized version reduced the time to 37.5s
AArchie
Original version of Hashrat hashed the same 3GB file at 36.9sWhile the optimized version did it in 27.7s
What Was Done?
In the end, all that was changed was the Makefile and Makefile.in in the libUseful-2.5 directory which was responsible for compiling the algorithms. The changes are as follows:
CFLAGS in both files were changed to “-g -O3” to enable additional optimizations by the compiler. Originally, CFLAGS was determined by the configure file with a default value of “-g -O2”.
Adding the flag -DSHA2_UNROLL_TRANSFORM to the line that compiles sha2.c (the SHA2 algorithm). This flag defines SHA2_UNROLL_TRANSFORM which causes the compiler to use the unrolled sha256transform function instead of the alternate slower version.
Going Forward
This pretty much wraps up Stage 2 of the project. For Stage 3, I’ll try to get my changes accepted by the upstream. Also, as I mentioned at the beginning of this post, I’ll also continue working on implementing inline assembly.
In part 1 of compiler optimization, I was wondering why only the second sha256Transform function was being used instead of the first one which was unrolled.
I decided to get off my butt and actually read. The 2nd transform function follows a #else directive. I followed it up and found the #ifdef directive:
So, that means that SHA2_UNROLL_TRANSFORM is not defined anywhere in this code. I searched up how to define this, and this led me to the comments on another program’s sha2.c file.
/*
* ASSERT NOTE:
* Some sanity checking code is included using assert(). On my FreeBSD
* system, this additional code can be removed by compiling with NDEBUG
* defined. Check your own systems manpage on assert() to see how to
* compile WITHOUT the sanity checking code on your system.
*
* UNROLLED TRANSFORM LOOP NOTE:
* You can define SHA2_UNROLL_TRANSFORM to use the unrolled transform
* loop version for the hash transform rounds (defined using macros
* later in this file). Either define on the command line, for example:
*
* cc -DSHA2_UNROLL_TRANSFORM -o sha2 sha2.c sha2prog.c
*
* or define below:
*
* #define SHA2_UNROLL_TRANSFORM
*
*/
The very same comments that are at the top of my sha2.c…
Following the instructions, I went into the Makefile in the algorithm directory and added -DSHA2_UNROLL_TRANSFORM as a flag for sha2.o.
After compiling the program again, I ran another test and got better results, as expected.
A full 3 seconds off from the -O3 build, or 4 seconds from the default build! I wonder why the author of this program didn’t enable this? Perhaps they just threw a bunch of algorithms in and called it a day? Maybe this was also a school project?















 Most of the information in that document reflects what Brave was like 3 years ago! It has changed drastically in that time.
Most of the information in that document reflects what Brave was like 3 years ago! It has changed drastically in that time.







 2 times
2 times 16 times.
16 times.